
On December 11, 2024, OpenAI experienced a service-wide outage that brought all of its offerings—API, ChatGPT, internal platforms—down for hours. The root cause? A new telemetry service deployment that triggered a chain reaction within their Kubernetes infrastructure, overwhelming control planes and crippling DNS-based service discovery.
Complexity at Scale: AI on Kubernetes
Kubernetes is regarded as the backbone of today’s large-scale AI services and platforms, from managing fleets of microservices to orchestrating inference at scale. Its promise of robust scheduling, scaling, and orchestration has propelled it into widespread use. But as the recent OpenAI incident reminds us, Kubernetes’ sophistication doesn’t come for free. Complex, interdependent systems can and will fail in unexpected ways.
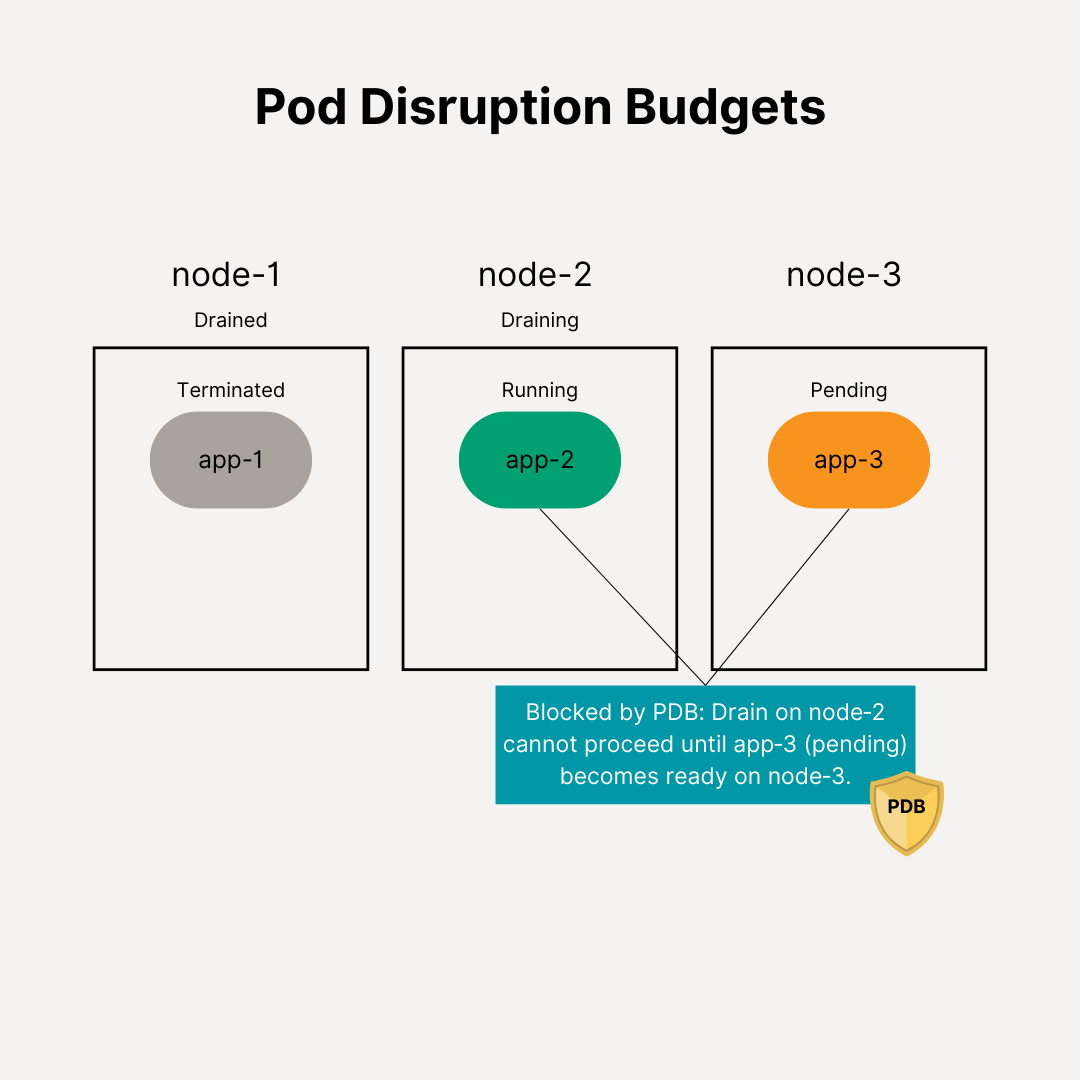
As environments grow—hundreds of clusters, thousands of nodes, and an intricate mesh of interdependent services—managing risk becomes exponentially more challenging. While Kubernetes is designed to handle complexity, certain architectural choices introduce fragile points of failure. DNS-based service discovery, custom add-ons (Istio, Cert-Manager, Nginx, Argo, Keycloak, and others), and their deep interactions with other add-ons, the underlying OS layers, and the Kubernetes control plane itself can create delicate dependency chains. If any one link weakens, the entire chain can collapse, triggering large-scale disruptions.
The Anatomy of the Outage
OpenAI’s outage stemmed from a new telemetry service that unexpectedly hammered the Kubernetes API servers with an overwhelming volume of requests. What might have been a routine deployment turned into a cluster-wide crisis when these API servers became the bottleneck. As DNS depends on the control plane, the resulting slowdown meant that workloads couldn’t discover or communicate with each other. The problem didn’t manifest immediately; DNS caching initially masked the issue, delaying the visibility of the incident and allowing the problematic rollout to continue. Once caches expired, the scale of the problem became clear, and recovery proved significantly more challenging.
Not an Isolated Incident
OpenAI’s experience isn’t isolated. Over the past several years, across various large-scale Kubernetes deployments, I’ve witnessed multiple outages driven by subtle interplays of misconfiguration, overconsumption of shared resources, and unexpected load on foundational components. In one environment, a CNI plugin ended up making excessive cloud provider API calls—quickly hitting hard rate limits and effectively “locking out” other clients attempting critical operations. In another scenario, Istio sidecars continuously queried the DNS service for service discovery. When that environment suddenly scaled to thousands of pods, the DNS service became overwhelmed, eventually OOMKilling itself under the load.
Such incidents highlight a common thread: the larger and more complex the environment, the more carefully we must guard against scenarios that compromise critical operational layers. These risks are “known unknowns”—operational risks that have already materialized elsewhere, but remain latent in your own infrastructure, lurking until a specific trigger (a scaling event, an added component, or a subtle configuration change) reveals their presence. With technology like Collective Learning, organizations can identify and remediate these latent risks before they escalate into costly outages.
Rethinking Operational Safety
For years, the industry has focused on accelerating the pace of software delivery—CI/CD pipelines, feature flags, canary deployments, and more. We’ve gotten incredibly good at shipping changes rapidly. Unfortunately, we haven’t always matched that pace with tooling and practices that ensure changes don’t break underlying infrastructure. This is where the concept of “Operational Safety” comes in.
Operational Safety isn’t about slowing down releases; it’s about building guardrails that prevent changes from cascading into catastrophic failures. This means implementing phased rollouts that start small and scale gradually, accompanied by continuous monitoring that checks not just resource consumption but also control-plane stability and DNS health.
It means acknowledging and preparing for the possibility that staging environments might not fully reflect production conditions—especially when production involves sprawling, globally distributed clusters. It also means building tooling that allows for quick remediation. In OpenAI’s case, restoring control-plane access was a significant hurdle; having “break-glass” procedures in place could shorten downtime and reduce its impact.
Beyond the Status Quo
What’s needed is a cultural shift: Operational Safety must be treated as a first-class engineering concern. It should be woven into the deployment pipeline, considered in architectural decisions, and included in routine testing. The end result won’t eliminate outages altogether—no system is perfect—but it can drastically reduce their frequency, impact, and duration.
Looking Forward
OpenAI has publicly shared their post-mortem, outlining steps they plan to take: phased rollouts, improved fault injection testing, emergency control-plane access mechanisms, and more resilient designs that decouple the control plane from critical workloads. While every organization’s architecture and processes are unique, the underlying lessons are universal.
In a world where software underpins everything from healthcare systems to financial markets, we must recognize that Operational Safety is not a luxury—it's a necessity. Our existing customers routinely detect and mitigate critical risks—whether latent or newly introduced by component changes, version updates, or infrastructure migrations—long before they cause failures. If you’re interested in learning more about it, reach out to me directly or connect with the Chkk team by clicking the ‘Book a Demo’ button below.
On December 11, 2024, OpenAI experienced a service-wide outage that brought all of its offerings—API, ChatGPT, internal platforms—down for hours. The root cause? A new telemetry service deployment that triggered a chain reaction within their Kubernetes infrastructure, overwhelming control planes and crippling DNS-based service discovery.
Complexity at Scale: AI on Kubernetes
Kubernetes is regarded as the backbone of today’s large-scale AI services and platforms, from managing fleets of microservices to orchestrating inference at scale. Its promise of robust scheduling, scaling, and orchestration has propelled it into widespread use. But as the recent OpenAI incident reminds us, Kubernetes’ sophistication doesn’t come for free. Complex, interdependent systems can and will fail in unexpected ways.
As environments grow—hundreds of clusters, thousands of nodes, and an intricate mesh of interdependent services—managing risk becomes exponentially more challenging. While Kubernetes is designed to handle complexity, certain architectural choices introduce fragile points of failure. DNS-based service discovery, custom add-ons (Istio, Cert-Manager, Nginx, Argo, Keycloak, and others), and their deep interactions with other add-ons, the underlying OS layers, and the Kubernetes control plane itself can create delicate dependency chains. If any one link weakens, the entire chain can collapse, triggering large-scale disruptions.
The Anatomy of the Outage
OpenAI’s outage stemmed from a new telemetry service that unexpectedly hammered the Kubernetes API servers with an overwhelming volume of requests. What might have been a routine deployment turned into a cluster-wide crisis when these API servers became the bottleneck. As DNS depends on the control plane, the resulting slowdown meant that workloads couldn’t discover or communicate with each other. The problem didn’t manifest immediately; DNS caching initially masked the issue, delaying the visibility of the incident and allowing the problematic rollout to continue. Once caches expired, the scale of the problem became clear, and recovery proved significantly more challenging.
Not an Isolated Incident
OpenAI’s experience isn’t isolated. Over the past several years, across various large-scale Kubernetes deployments, I’ve witnessed multiple outages driven by subtle interplays of misconfiguration, overconsumption of shared resources, and unexpected load on foundational components. In one environment, a CNI plugin ended up making excessive cloud provider API calls—quickly hitting hard rate limits and effectively “locking out” other clients attempting critical operations. In another scenario, Istio sidecars continuously queried the DNS service for service discovery. When that environment suddenly scaled to thousands of pods, the DNS service became overwhelmed, eventually OOMKilling itself under the load.
Such incidents highlight a common thread: the larger and more complex the environment, the more carefully we must guard against scenarios that compromise critical operational layers. These risks are “known unknowns”—operational risks that have already materialized elsewhere, but remain latent in your own infrastructure, lurking until a specific trigger (a scaling event, an added component, or a subtle configuration change) reveals their presence. With technology like Collective Learning, organizations can identify and remediate these latent risks before they escalate into costly outages.
Rethinking Operational Safety
For years, the industry has focused on accelerating the pace of software delivery—CI/CD pipelines, feature flags, canary deployments, and more. We’ve gotten incredibly good at shipping changes rapidly. Unfortunately, we haven’t always matched that pace with tooling and practices that ensure changes don’t break underlying infrastructure. This is where the concept of “Operational Safety” comes in.
Operational Safety isn’t about slowing down releases; it’s about building guardrails that prevent changes from cascading into catastrophic failures. This means implementing phased rollouts that start small and scale gradually, accompanied by continuous monitoring that checks not just resource consumption but also control-plane stability and DNS health.
It means acknowledging and preparing for the possibility that staging environments might not fully reflect production conditions—especially when production involves sprawling, globally distributed clusters. It also means building tooling that allows for quick remediation. In OpenAI’s case, restoring control-plane access was a significant hurdle; having “break-glass” procedures in place could shorten downtime and reduce its impact.
Beyond the Status Quo
What’s needed is a cultural shift: Operational Safety must be treated as a first-class engineering concern. It should be woven into the deployment pipeline, considered in architectural decisions, and included in routine testing. The end result won’t eliminate outages altogether—no system is perfect—but it can drastically reduce their frequency, impact, and duration.
Looking Forward
OpenAI has publicly shared their post-mortem, outlining steps they plan to take: phased rollouts, improved fault injection testing, emergency control-plane access mechanisms, and more resilient designs that decouple the control plane from critical workloads. While every organization’s architecture and processes are unique, the underlying lessons are universal.
In a world where software underpins everything from healthcare systems to financial markets, we must recognize that Operational Safety is not a luxury—it's a necessity. Our existing customers routinely detect and mitigate critical risks—whether latent or newly introduced by component changes, version updates, or infrastructure migrations—long before they cause failures. If you’re interested in learning more about it, reach out to me directly or connect with the Chkk team by clicking the ‘Book a Demo’ button below.




.png)




.png)


.png)


















.png)





.jpg)

